
Building Resilient Distributed Systems
When I first started breaking down massive monolithic applications, I quickly realized that building microservices is easy, but building them correctly is incredibly hard. Implementing spring boot microservices architecture best practices is what separates a robust, highly available distributed system from a chaotic, hard-to-debug “distributed monolith.”
In this guide, I’m going to walk you through the architectural patterns, code-level configurations, and hard-learned lessons from running Spring Boot microservices in production. Whether you’re starting from scratch or refactoring a legacy system, these principles will help you avoid the most common pitfalls of distributed system design.
Fundamentals of Microservices Design
Before we write a single line of Java or Kotlin, we need to get the architectural foundations right. Spring Boot makes spinning up a web server trivial, but deciding what goes into that server is the real challenge.
1. Domain-Driven Design (DDD) and Bounded Contexts
A microservice should encapsulate a single business capability. I rely heavily on Domain-Driven Design (DDD) to define my bounded contexts. For example, in an e-commerce platform, the OrderService and InventoryService are completely separate bounded contexts. They shouldn’t share database tables, and they shouldn’t share domain entities. If you find yourself frequently updating three different services to release one feature, your service boundaries are wrong.
2. The Database-per-Service Pattern
This is arguably the most critical and most frequently violated best practice. Every microservice must own its own data. If your UserService and BillingService are both reading and writing to the same SQL database, you have a distributed monolith.
By giving each service its own datastore (e.g., PostgreSQL for relational data, MongoDB for documents, Redis for caching), you ensure loose coupling. If the InventoryService database goes down, the UserService remains fully functional.
Deep Dive: Core Spring Boot Microservices Architecture Best Practices
Let’s dive into the practical implementation of these concepts using the Spring ecosystem.
Chapter 1: Inter-Service Communication
Microservices need to talk to each other, but how they do so dictates the resilience of your entire system. I generally split communication into two categories:
- Synchronous (REST / gRPC): Best for querying data that is needed immediately (e.g., a frontend gateway fetching a user’s profile).
- Asynchronous (Event-Driven): Best for state changes and commands (e.g., an order being placed).
For synchronous calls, avoid the legacy RestTemplate. In modern Spring Boot 3.x, use the new RestClient or the reactive WebClient. Here’s a quick example of a resilient synchronous call using RestClient with proper timeout configurations:
@Configuration
public class RestClientConfig {
@Bean
public RestClient customRestClient() {
return RestClient.builder()
.baseUrl("http://inventory-service")
.requestFactory(new HttpComponentsClientHttpRequestFactory() {{
setConnectTimeout(2000);
setReadTimeout(3000);
}})
.defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.build();
}
}However, my strongest recommendation is to default to event-driven architecture using Kafka or RabbitMQ whenever possible. When the OrderService publishes an OrderCreatedEvent, it doesn’t care if the NotificationService is temporarily down. The message broker handles the queue, ensuring eventual consistency without strict temporal coupling.
Chapter 2: Managing Configuration
Managing application.yml files across 20 different repositories is a nightmare. Externalize your configuration.
While you can mount Kubernetes ConfigMaps, I often prefer Spring Cloud Config for its tight integration with the Spring ecosystem. It allows you to store your configurations in a central Git repository and refresh them at runtime without restarting the JVM. If you’re weighing your options on whether to adopt the full Spring Cloud suite, check out my comprehensive spring cloud vs spring boot comparison to see if the added complexity is worth it for your team.
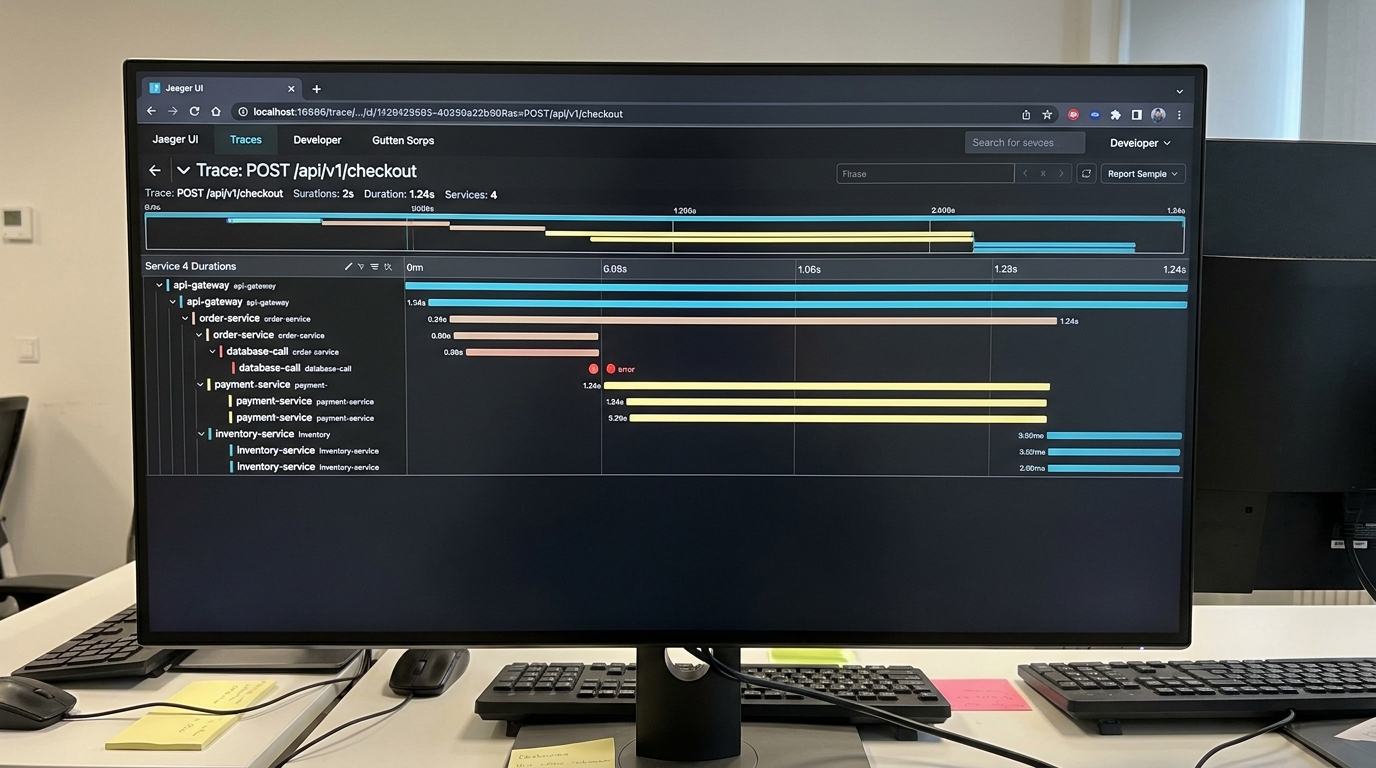
Chapter 3: Observability and Tracing
When a user complains that “checkout is slow,” how do you know which of your 15 microservices is the bottleneck? You cannot run microservices in production without distributed tracing.
In Spring Boot 3, Micrometer Tracing has replaced Spring Cloud Sleuth. By integrating Micrometer with Zipkin or Jaeger, every incoming request gets a unique traceId that propagates through all downstream services.
As I detail in my guide on distributed tracing with spring boot, adding the dependencies is simple:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
</dependency>This auto-configures your application to append trace IDs to your SLF4J logs and export span data to your tracing server.
Chapter 4: Resilience and Fault Tolerance
Network partitions happen. Downstream services will fail. You must design for failure using the Circuit Breaker pattern. Using Resilience4j (which replaced Netflix Hystrix), you can prevent cascading failures. If the RecommendationService is timing out, the ProductService should short-circuit the request and return a fallback (like a hardcoded list of popular products) rather than tying up its own thread pool waiting for a timeout.
Implementation Principles: API Gateways
Never expose your raw microservices directly to the client. Always route traffic through an API Gateway. The gateway acts as a reverse proxy, handling cross-cutting concerns like:
- Authentication and JWT validation
- Rate limiting
- Request routing and load balancing
- CORS configuration
You can use Spring Cloud Gateway to build a non-blocking, highly concurrent gateway. For a deeper dive into routing strategies, read my breakdown of API Gateway patterns.
Deployment & Containerization Tools
Spring Boot 3 natively supports generating optimized Docker images using Cloud Native Buildpacks (via ./mvnw spring-boot:build-image) and GraalVM native images for lightning-fast startup times.
For orchestration, Kubernetes is the industry standard. Ensure your Spring Boot services expose health endpoints via Spring Boot Actuator (/actuator/health) so Kubernetes can manage Liveness and Readiness probes. Proper deploying Spring Boot on Kubernetes ensures zero-downtime rolling updates.
Case Study: Scaling an E-Commerce Backend
Last year, my team migrated a legacy e-commerce monolith to a Spring Boot microservices architecture. By strictly adhering to the database-per-service pattern and utilizing asynchronous communication via Kafka for the checkout flow, we achieved incredible results. During Black Friday, the InventoryService experienced a 10x traffic spike. Because we utilized bounded contexts and horizontal pod autoscaling in Kubernetes, that specific service scaled up independently without affecting the CPU or memory footprint of the rest of the application.
Final Thoughts
Adopting spring boot microservices architecture best practices requires a mindset shift. It’s less about the code you write and more about how you define boundaries, manage data, and handle failure. Start small—strangle the monolith one bounded context at a time, automate your deployments, and never skip observability.
Frequently Asked Questions
It is a microservices best practice where every microservice must own its own data. This ensures loose coupling and independent scalability across the distributed system, avoiding the common anti-pattern of a distributed monolith.
An API Gateway acts as a reverse proxy and unified entry point for your application. It handles cross-cutting concerns like authentication, JWT validation, rate limiting, and request routing, ensuring you never expose raw microservices directly to the client.
Spring Boot 3 utilizes Micrometer Tracing (replacing Spring Cloud Sleuth). By integrating it with tools like Zipkin or Jaeger, you can append unique trace IDs to requests and propagate them across all downstream services, simplifying observability.