
Understanding the Relationship: It’s Not A vs B
When developers search for spring data jpa vs hibernate performance, they are often asking a trick question. Hibernate is an implementation of the Java Persistence API (JPA) specification, while Spring Data JPA is an abstraction layer that sits on top of Hibernate. In my experience, the ‘performance’ difference isn’t about which one executes SQL faster, but rather how much overhead the Spring abstraction adds and how easily each allows you to shoot yourself in the foot with inefficient queries.
After years of building high-throughput microservices, I’ve realized that the performance bottleneck is rarely the library itself. Instead, it’s the 1,000 hidden SQL calls caused by a lack of understanding of the persistence context. In this guide, I’ll break down the architectural differences and show you where the real milliseconds are lost.
Hibernate: The Powerhouse Engine
Hibernate is the heavy lifter. It handles the mapping of Java objects to database tables, manages the First-Level Cache (Session), and generates the actual SQL dialect for your database. When you use Hibernate directly, you have total control over the SessionFactory and Session.
Pros of Raw Hibernate
- Fine-Grained Control: You can access specific Hibernate features like
StatelessSessionfor bulk processing, which bypasses the persistence context for better memory management. - Lower Memory Footprint: By avoiding the Spring proxy layer, you save a negligible but measurable amount of heap space in extreme high-concurrency scenarios.
- Complex Query Capabilities: Accessing the Criteria API or HQL directly sometimes feels more natural when building dynamic, multi-filter search engines.
Cons of Raw Hibernate
- Boilerplate Code: You’ll spend more time managing transactions and session boundaries manually.
- Steep Learning Curve: Understanding the lifecycle of entities (Transient, Persistent, Detached) requires deep knowledge.
Spring Data JPA: The Modern Abstraction
Spring Data JPA makes our lives easier by providing the JpaRepository interface. It reduces the code required to implement data access layers to almost zero. But does this convenience come at a price?
Pros of Spring Data JPA
- Developer Productivity: Query methods (e.g.,
findByEmail) generate SQL automatically, saving hours of development time. - Consistency: It forces a standard pattern across your team, making the codebase easier to maintain.
- Integration: It works seamlessly with other Spring components. For instance, pairing it with a spring boot redis caching strategy is trivial compared to manual integration.
Cons of Spring Data JPA
- Proxy Overhead: Every repository call goes through a series of interceptors and proxies.
- Hidden Inefficiency: It’s very easy to write a query method that looks simple but triggers a massive join or the dreaded N+1 problem.
Performance Benchmarks: The Reality Check
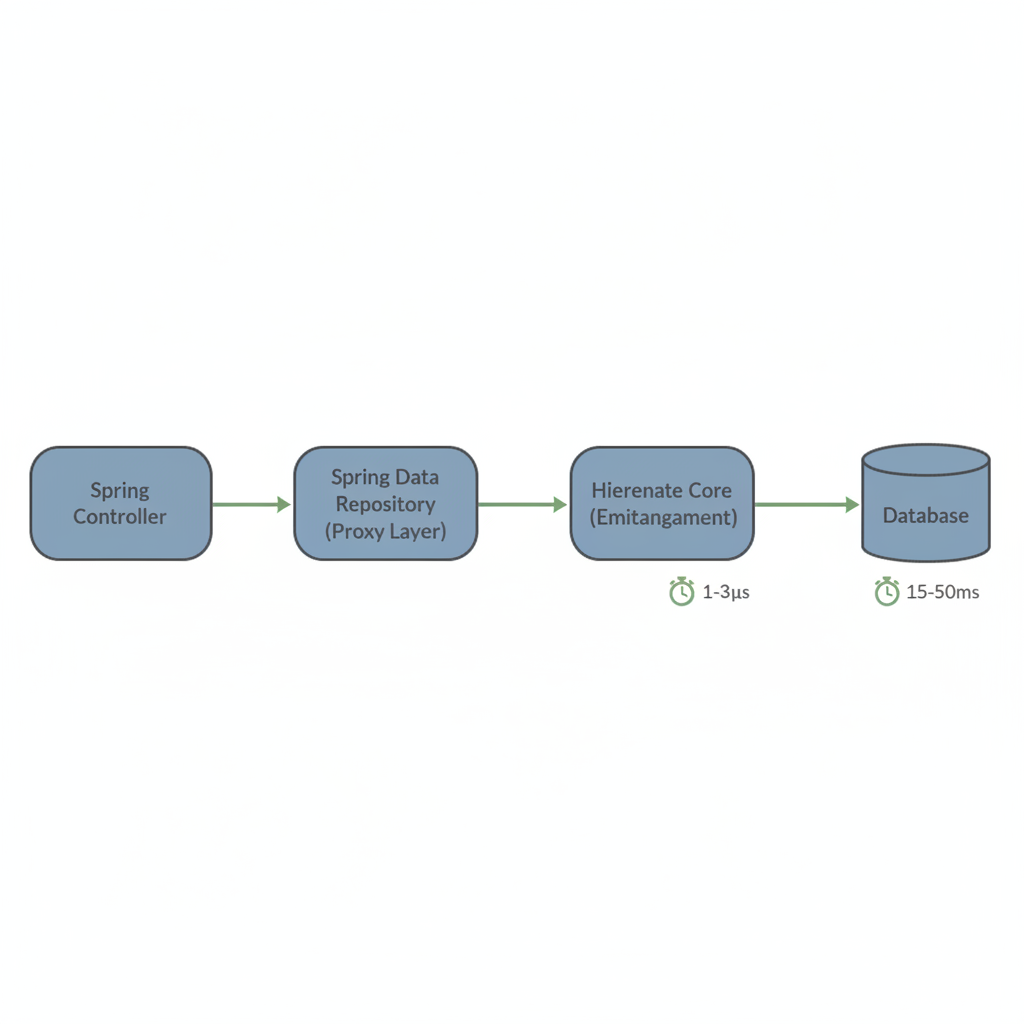
In most benchmarks, the overhead of Spring Data JPA’s repository proxy is roughly 1-3 microseconds per call. Unless you are building a high-frequency trading platform, this is irrelevant compared to the 10-50 milliseconds your database takes to execute a query. As shown in the architectural diagram below, the layers add complexity, but the database remains the true bottleneck.
The real performance gap appears in how you handle data. For example, using @Query with JOIN FETCH in Spring Data JPA is just as fast as HQL in Hibernate. However, if you rely on default lazy loading without proper fetching strategies, your application will crawl regardless of the tool you choose.
Comparison Table
| Feature | Hibernate (Raw) | Spring Data JPA |
|---|---|---|
| Abstraction Level | Low (Implementation) | High (Abstraction) |
| Proxy Overhead | None | Minimal (~µs) |
| Boilerplate | High | Very Low |
| N+1 Vulnerability | High | High (Easier to ignore) |
| Learning Curve | High | Low |
How to Optimize Performance in Both
Regardless of your choice, performance tuning follows the same principles. First, always monitor your generated SQL. I recommend using datasource-proxy or setting logging.level.org.hibernate.SQL=DEBUG during development.
Second, ensure your testing environment reflects reality. Using a spring boot testing with testcontainers tutorial setup allows you to run performance tests against a real PostgreSQL or MySQL instance rather than H2, which often hides indexing issues.
Third, use projections. If you only need two columns, don’t fetch the entire entity. Both Hibernate and Spring Data JPA support DTO projections, which significantly reduce memory pressure and network transfer time.
My Verdict: Which Should You Choose?
In my professional opinion, Spring Data JPA is the winner for 99% of applications. The productivity gains far outweigh the micro-overhead of the abstraction layer. If you find a specific bottleneck, you can always inject an EntityManager into a custom repository and write native Hibernate code for that specific hot path.
Choose raw Hibernate only if you are building a standalone library that cannot depend on the Spring Framework or if you are working in an extremely resource-constrained environment where every kilobyte of RAM matters.