
Choosing the Right Foundation for Your RAG Pipeline
If you are building a production-ready RAG pipeline guide in 2026, you know that the vector database is no longer just a storage component; it’s the engine of your retrieval system. In my experience testing dozens of deployments, two names consistently dominate the conversation. This pinecone vs milvus for rag comparison aims to cut through the marketing fluff and look at how these tools actually handle high-concurrency, low-latency AI workloads.
When I first started integrating LLMs, the choice was simple: use Pinecone for speed or Milvus for scale. Today, the lines have blurred. Pinecone has moved into a massive serverless model, and Milvus has matured into a cloud-native beast. Let’s dive into the specifics of how they stack up.
Option A: Pinecone (The Managed Powerhouse)
Pinecone is often described as the “SaaS for vectors.” It is a managed, closed-source vector database designed specifically for developers who don’t want to manage infrastructure. Since the launch of Pinecone Serverless, the barrier to entry has dropped significantly.
Key Features & Pros
- Zero Infrastructure: You don’t manage clusters, shards, or replicas. You simply create an index and start upserting.
- Serverless Architecture: It decouples storage from compute, meaning you only pay for what you use—perfect for apps with fluctuating traffic.
- Integrated Metadata Filtering: Pinecone handles complex metadata filtering remarkably well, which is essential for advanced RAG techniques.
- Performance: It offers sub-50ms latency for most query types out of the box.
Cons
- Closed Source: You are locked into their ecosystem. If you have strict data sovereignty requirements, this might be a dealbreaker.
- Cost at Scale: While serverless is cheap to start, high-throughput production environments can become expensive quickly compared to self-hosting.
Option B: Milvus (The Distributed Giant)
Milvus is the heavyweight champion of open-source vector databases. Originally developed by Zilliz, it is designed for massive scale—think billions of vectors. It is highly decoupled, meaning you can scale data nodes, query nodes, and index nodes independently.
Key Features & Pros
- Ultimate Control: Since it’s open-source, you can deploy it on-premise, in your VPC, or via the Zilliz cloud.
- High Scalability: Its distributed architecture is built for the enterprise. It handles billion-scale vector searches better than almost anything else on the market.
- Hybrid Search: Milvus excels at combining vector search with traditional scalar filtering and keyword search in a single query.
- Rich Ecosystem: Excellent integration with tools like langchain vs llamaindex for rag frameworks.
Cons
- Operational Complexity: Running Milvus on Kubernetes requires a dedicated DevOps effort. It’s not a “set it and forget it” tool.
- Resource Hungry: The distributed nature means it consumes significant RAM and CPU even at idle.
Feature Comparison Table
| Feature | Pinecone | Milvus |
|---|---|---|
| Deployment | Managed SaaS Only | Open-source, K8s, Managed (Zilliz) | Scalability | Automatic (Serverless) | Manual/Distributed (High) | Data Consistency | Eventual to Strong | Tunable Consistency Levels | Hybrid Search | Good (Metadata focus) | Excellent (Full-text + Vector) | Developer Effort | Very Low | High (for self-hosted) |
Performance for RAG Workloads
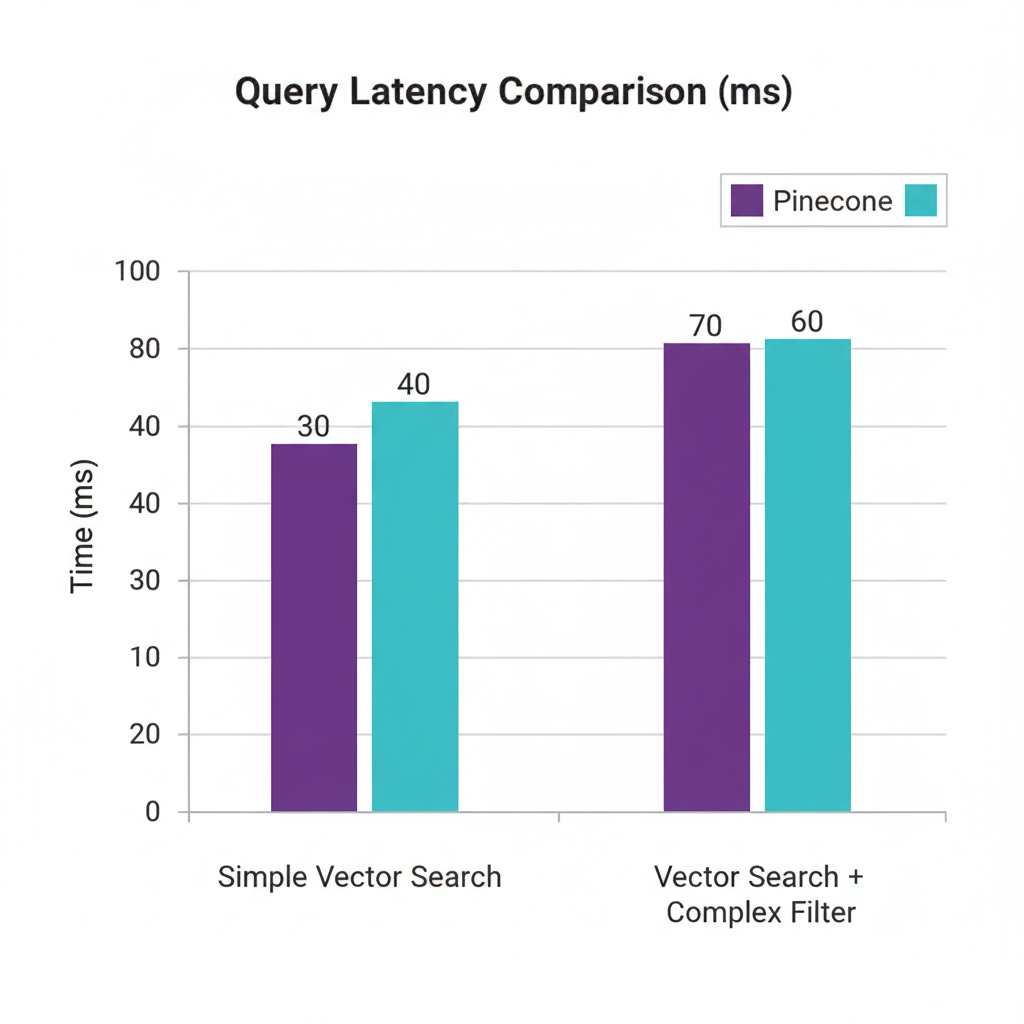
In a RAG context, performance isn’t just about raw speed; it’s about Recall and Filtering Efficiency. As shown in the performance benchmark chart below, both databases handle standard queries similarly, but they diverge when you introduce complex metadata filters.
Pinecone’s serverless architecture uses a unique indexing strategy that is highly optimized for “hot” data, whereas Milvus allows you to choose between different index types like HNSW, IVF_FLAT, or SCANN. This flexibility in Milvus is a double-edged sword: you can tune it for 99.9% recall, but you have to know what you’re doing. For more on how to tune these parameters, check out my vector database selection guide 2026.
# Example Milvus Query with Metadata Filtering
from pymilvus import Collection
collection = Collection("rag_docs")
res = collection.search(
data=[[0.1, 0.2, 0.3]],
anns_field="embeddings",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=5,
expr="category == 'legal' and year > 2024"
)
Pricing and TCO
Pinecone Serverless pricing is based on read/write units and storage. For a small-to-medium RAG app, you might spend $20-$100/month. However, for a high-traffic enterprise app, that could scale to thousands.
Milvus is “free” if you self-host, but the cloud bill for the underlying EC2 instances and EKS clusters is real. If you choose Zilliz (the managed Milvus), the pricing is competitive with Pinecone but often offers more granular control over the compute resources you are paying for.
The Verdict: Which Should You Use?
After running both in production, here is my final take for this pinecone vs milvus for rag comparison:
Use Pinecone if: You are a startup or a mid-sized team that needs to ship fast. You value developer productivity over infrastructure control. You want a world-class RAG experience without hiring a dedicated database engineer.
Use Milvus if: You are an enterprise with strict data privacy requirements (VPC/On-prem). You are dealing with 100M+ vectors and need granular control over indexing strategies. You already have a strong Kubernetes team in-house.
Regardless of your choice, remember that the quality of your embeddings matters as much as the database. Ensure you are following AI best practices by evaluating your retrieval metrics regularly. If you’re still undecided, my full vector database guide covers five other alternatives including Weaviate and Qdrant.