
Introduction: The Tipping Point of LLM Costs
In 2026, the AI landscape has shifted from “how do we use it?” to “how do we afford it?” For many developers and businesses, the initial convenience of OpenAI or Anthropic APIs eventually hits a ceiling where monthly bills exceed the cost of a high-end GPU cluster. I’ve spent the last quarter auditing our infrastructure at ajmani.dev, and I’ve realized that a proper cost analysis of self-hosting LLMs is no longer just about hardware—it’s about the total cost of ownership (TCO).
Whether you are deciding between open source vs closed source llms for business or simply trying to escape the constraints of rate limits, understanding the financial break-even point is critical. In this deep dive, I’ll share the exact benchmarks and cost models I use to determine when self-hosting makes financial sense.
The Challenge: The Hidden Taxes of API Dependency
API pricing models are designed to be low-friction at entry but high-friction at scale. When you’re processing millions of tokens a day, you aren’t just paying for compute; you’re paying for the provider’s margin, their R&D, and their massive overhead. Furthermore, if you haven’t been optimizing llm token usage cost, your monthly burn could be 30-40% higher than necessary.
The primary challenges include:
- Unpredictable Billing: Traffic spikes can lead to massive, unexpected invoices.
- Data Privacy Premiums: Enterprise-grade privacy on closed models often comes with a significant price hike.
- Rate Limiting: Scaling your application often requires negotiation for higher tiers, adding administrative delay.
Solution Overview: Components of the Self-Hosting TCO
When performing a cost analysis of self-hosting LLMs, you must look beyond the sticker price of an NVIDIA RTX 5090 or H100. A true TCO includes:
- Capital Expenditure (CapEx): The upfront cost of GPUs, RAM, and storage.
- Operational Expenditure (OpEx): Electricity, cooling, and data center rack space (or home office power).
- Maintenance & Talent: The hourly cost of the engineer (you or your team) managing the stack.
- Software Overhead: Licensing for orchestration tools or managed GPU clouds like Lambda or RunPod.
Techniques: Optimizing VRAM and Compute
The most expensive part of self-hosting is VRAM. In my experience, using 4-bit quantization (via AWQ or GGUF) is the single most effective way to slash your hardware requirements. For example, a Llama 3 70B model in full 16-bit precision requires ~140GB of VRAM, necessitating multiple A100s. At 4-bit quantization, it fits comfortably on two RTX 5090s (assuming 32GB/card in 2026) or a single Mac Studio M2/M3 Ultra.
# Example: Calculating VRAM for 4-bit Quantization
# Model: 70 Billion Parameters
# Precision: 4-bit (approx 0.7 bytes per parameter including overhead)
params = 70_000_000_000
bits = 4
overhead = 1.2 # KV Cache and activation buffer
total_vram_gb = (params * (bits / 8) * overhead) / 10**9
print(f"Required VRAM: {total_vram_gb:.2f} GB")
# Output: Required VRAM: 42.00 GB
By leveraging quantization, you can run high-performance models on consumer-grade hardware, which changes the ROI calculation significantly.
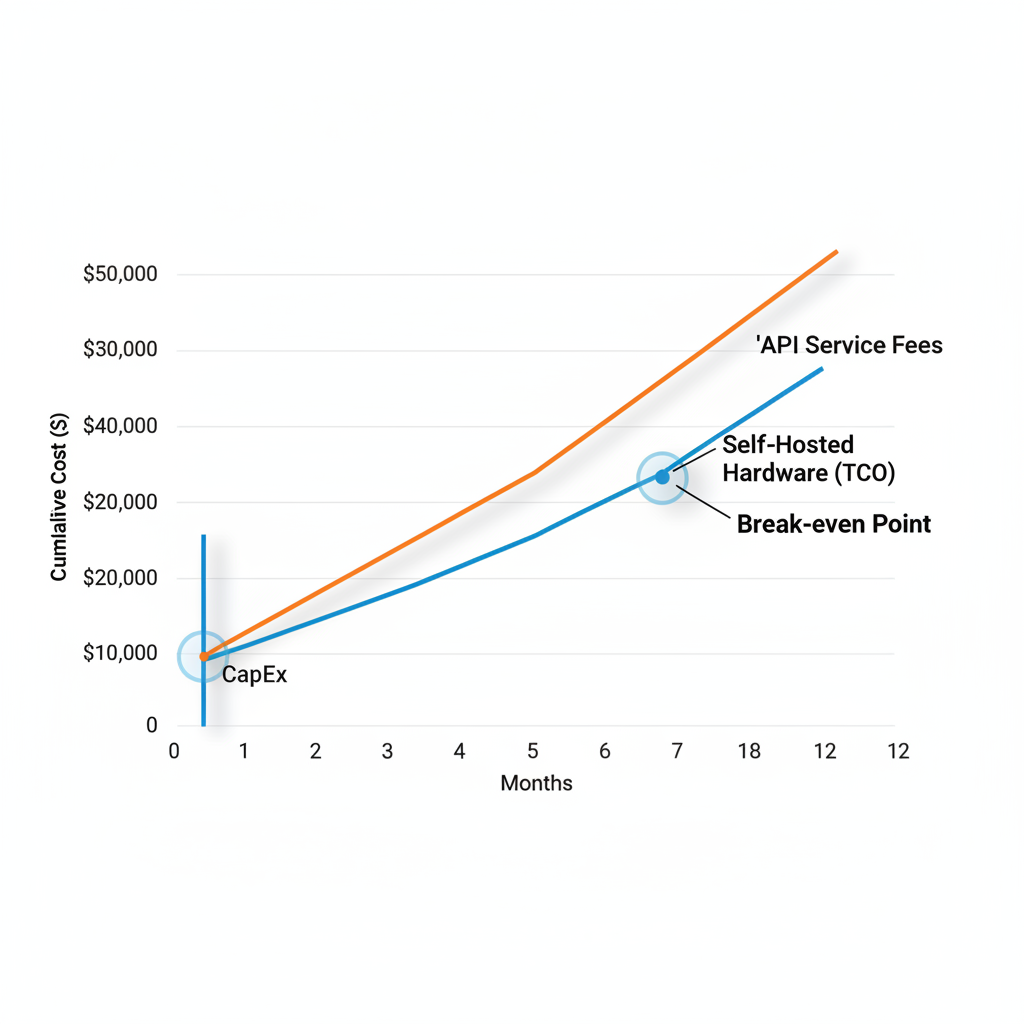
Implementation: A Comparative Benchmark
Let’s look at a real-world scenario. If your application processes 10 million tokens per day (roughly the volume of a mid-sized SaaS customer support bot), here is how the costs stack up over a 12-month period.
| Metric | Managed API (GPT-4o) | Self-Hosted (Llama 3 70B on 2x RTX 5090) |
|---|---|---|
| Upfront Cost | $0 | ~$5,500 (Hardware + Rack) |
| Monthly Cost | ~$4,500 (Based on $15/1M tokens) | ~$150 (Electricity + ISP) |
| 12-Month Total | $54,000 | $7,300 |
As shown in the table above, the break-even point occurs in less than two months. However, this assumes you have the technical capability to maintain 99.9% uptime yourself. If you are also motivated by data sovereignty, you should read more on should i use open source llms for privacy to justify the non-monetary ROI.
Case Study: The “Local-First” Transition
Last year, I assisted a startup transitioning from a $12,000/month OpenAI bill to a localized cluster of three nodes running vLLM. We utilized Llama 3 70B quantized to 4-bit. While the initial setup took two weeks of engineering time (a hidden cost of roughly $8,000 in salary), the ongoing savings were astronomical. By month six, they had saved over $50,000, which was immediately reinvested into fine-tuning their own proprietary models.
Pitfalls to Avoid
A cost analysis of self-hosting LLMs isn’t complete without acknowledging the risks. I’ve seen many projects fail because they ignored these factors:
- Depreciation: AI hardware loses value fast. Your $2,000 GPU today might be worth $800 in 18 months.
- The “Fragility” Cost: If your local server goes down at 3 AM on a Sunday, you are the on-call engineer. APIs rarely have this problem.
- Cooling and Noise: A dual-GPU setup under constant load generates significant heat. If you’re running this in an office, your HVAC costs will rise.
Final Verdict
If your token volume is low, stick to APIs. The convenience is worth the markup. But if you are processing millions of tokens daily, or if your data is highly sensitive, self-hosting is the only path to long-term sustainability. Start by experimenting with consumer GPUs or “rent-to-own” cloud GPU instances to validate your stack before committing to a $10,000 hardware purchase.