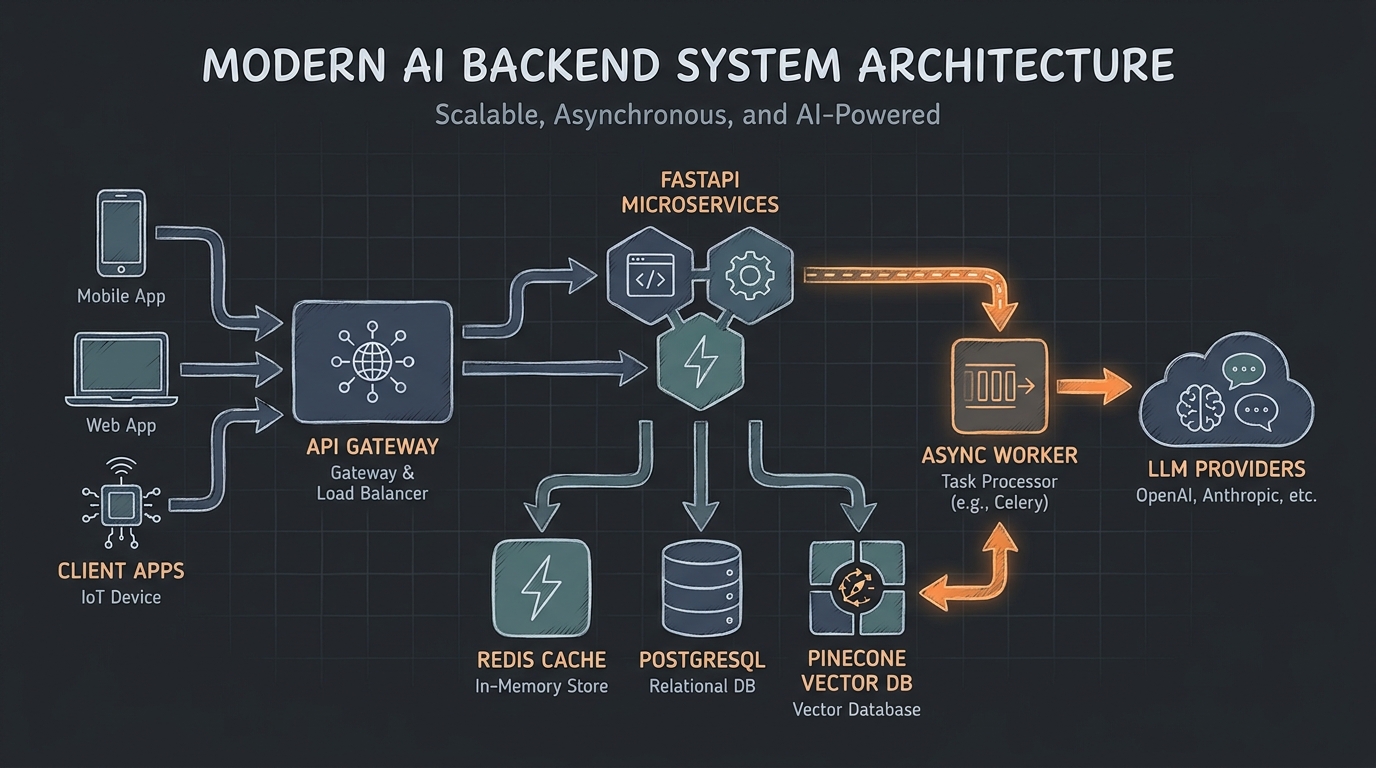
Moving Beyond the Prototype
I’ve spent the last few years helping companies transition from traditional CRUD applications to AI-first architectures. If you are researching AI backend engineering consulting services, it is likely because you’ve hit a wall. You’ve realized that wrapping an OpenAI API call in a basic Express route is great for a weekend hackathon, but it crumbles in production.
In my experience, building backends for Generative AI introduces an entirely new class of challenges. Response times jump from 50ms to 5 seconds. Stateless requests suddenly require complex context management. Security isn’t just about SQL injection anymore; it’s about prompt injection and data leakage.
In this guide, I’ll walk you through exactly what professional AI backend consulting looks like, the core architectural shifts you need to make, and how to scale your infrastructure for generative workloads.
What Do AI Backend Engineering Consulting Services Actually Deliver?
When clients hire me for AI backend engineering consulting services, they usually have a working prototype that is too slow, too expensive, or too fragile to release to real users. A professional consultant bridges the gap between “it works on my machine” and “it serves 10,000 enterprise users securely.”
Here are the primary deliverables in a typical engagement:
- Architecture Modernization: Shifting from synchronous request/response cycles to asynchronous event-driven architectures and streaming (Server-Sent Events).
- Cost & Rate Limit Management: Implementing semantic caching, token counting, and fallback routing to keep LLM bills manageable.
- Retrieval-Augmented Generation (RAG) Pipelines: Designing efficient ingestion, chunking, and vector database querying systems.
- Enterprise Security: Adding PII redaction layers and robust guardrails before prompts ever reach an external API.
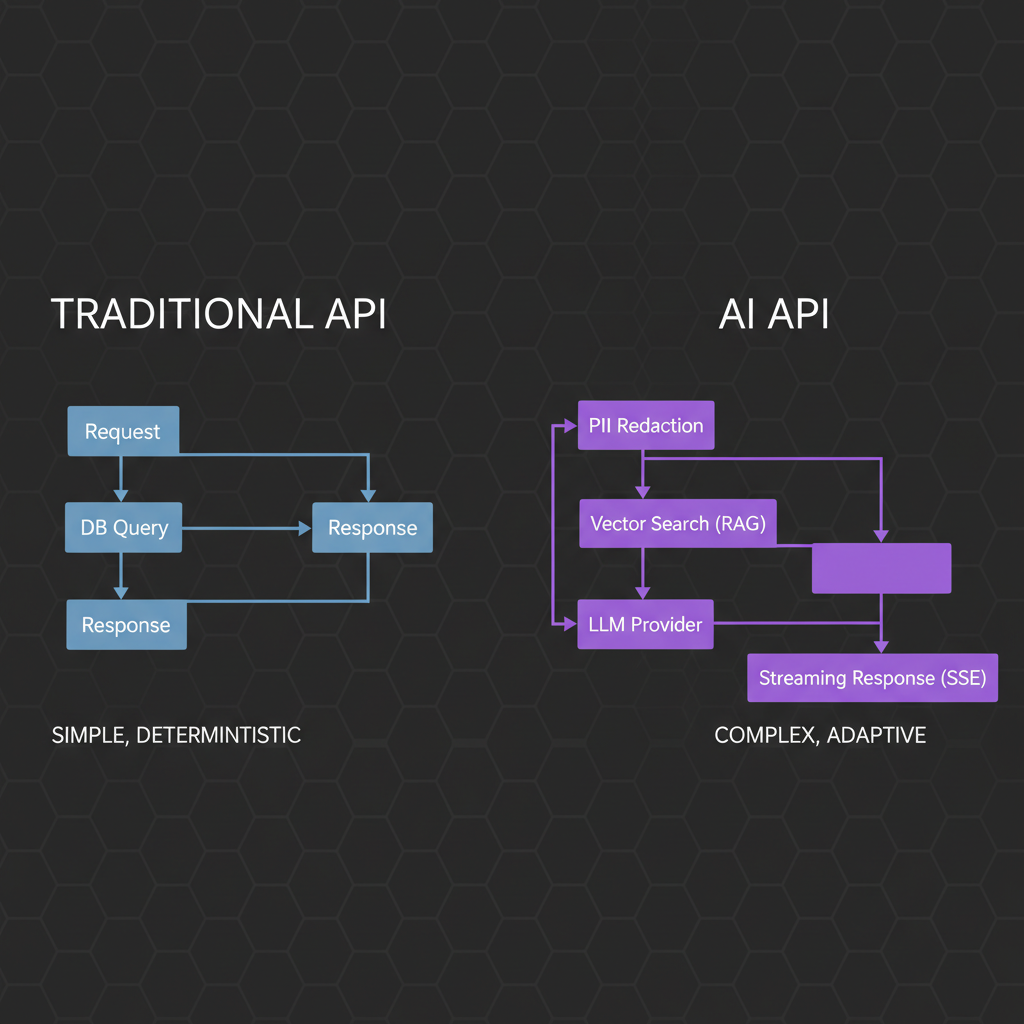
Deep Dive 1: Architecture for AI Workloads
Traditional APIs are synchronous. The client asks for user data, the server queries the database, and 30ms later, the client gets a JSON payload. AI breaks this paradigm entirely.
Streaming vs. Polling vs. WebSockets
Because LLM generation takes seconds (or minutes), holding HTTP requests open is a recipe for server timeouts and terrible UX. In my consulting engagements, I almost always transition clients to Server-Sent Events (SSE) for text generation.
Here is a basic example of how I structure an SSE endpoint in Node.js to stream tokens to the client:
app.get('/api/generate', async (req, res) => {
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
const stream = await llmProvider.generateStream(req.query.prompt);
for await (const chunk of stream) {
res.write(`data: ${JSON.stringify({ token: chunk })}\n\n`);
}
res.write('data: [DONE]\n\n');
res.end();
});For more complex, multi-step agentic workflows (like generating a report that requires web scraping, analyzing, and writing), I architect asynchronous queues using Celery (Python) or BullMQ (Node.js). If you’re building bespoke solutions, exploring custom AI model API development is crucial for setting up the right foundational architecture.
Deep Dive 2: Performance, Caching, and Scalability
Scalability in traditional backends means adding more database replicas. Scalability in AI backends means protecting your external LLM provider quotas and reducing latency.
One of the first things I implement is Semantic Caching. Unlike standard Redis caching which requires an exact string match, semantic caching uses a faster, cheaper embedding model to compare the meaning of the incoming prompt against previous prompts.
If User A asks “How do I reset my password?” and User B asks “What is the password reset process?”, semantic caching serves User B the cached answer in 50ms, entirely bypassing the expensive LLM call. This is a critical component of scaling backend APIs for generative AI efficiently.
Deep Dive 3: Enterprise AI Security
Security is the number one reason enterprise companies seek AI backend engineering consulting services. You cannot simply pipe user input directly into an LLM.
A production-ready pipeline requires a “middleware” approach to AI requests:
- PII Redaction: Scanning prompts for emails, SSNs, and phone numbers and replacing them with tokens before sending them to OpenAI or Anthropic.
- Prompt Injection Defense: Using specialized smaller models or heuristics to detect malicious “ignore all previous instructions” payloads.
- Output Guardrails: Validating the AI’s response against a strict JSON schema or checking for toxic content before returning it to the user.
I cover this extensively in my guide on API security for large language models, which outlines the exact middleware patterns I use in production.
The Implementation Process: How I Consult
If you’re wondering what an actual consulting engagement looks like, here is my standard methodology:
- Discovery & Audit (1-2 weeks): Reviewing existing code, identifying rate-limit bottlenecks, and analyzing token costs.
- Architecture Design (1 week): Delivering a comprehensive system design document detailing the transition to async processing, vector DB integration, and caching layers.
- Implementation & Hardening (4-8 weeks): Writing the core backend infrastructure. This isn’t just advisory; I prefer to get my hands dirty and build the critical path APIs alongside your engineering team.
- Handoff & Training (1 week): Ensuring your in-house team understands how to monitor vector drift, update embeddings, and manage the new infrastructure.
The Essential AI Backend Tech Stack
While the landscape changes rapidly, my current recommended tech stack for building robust AI backends includes:
- Compute: FastAPI (Python) or NestJS (Node) – both offer excellent support for async operations and streaming.
- Vector Databases: Pinecone (for managed ease of use) or Qdrant/Milvus (for self-hosted performance).
- Orchestration: LangChain or LlamaIndex, though I increasingly recommend building custom orchestrators to avoid the abstraction bloat these libraries often introduce.
- Observability: Langfuse or Helicone for tracing token usage and LLM latency.
Final Verdict: Do You Need a Consultant?
If your AI feature is a non-critical “nice-to-have” side project, you probably don’t need dedicated AI backend engineering consulting services. Your in-house team can likely hack together a solution using basic API wrappers.
However, if generative AI is the core value proposition of your product, the stakes are much higher. Poor architecture will lead to unmanageable cloud bills, catastrophic latency that ruins user experience, or severe security breaches via prompt injection. Bringing in an expert to architect the foundation correctly will save you months of technical debt. If you are ready to productionize your AI backend, reach out for a consultation and let’s discuss your architecture.
Frequently Asked Questions
What exactly do AI backend engineering consulting services cover?
These services focus on productionizing AI applications. This includes transitioning architectures to support streaming/async workloads, implementing semantic caching to reduce API costs, building secure RAG (Retrieval-Augmented Generation) pipelines, and setting up guardrails to prevent prompt injection and PII leakage.
Why can’t I just use standard REST APIs for LLM calls?
Standard REST APIs are designed for quick, synchronous responses (under 200ms). LLM generation often takes several seconds to minutes. If you use standard REST, client connections will time out, and your servers will exhaust their connection pools. AI backends require streaming (Server-Sent Events) or asynchronous task queues.
How do you handle rate limits from OpenAI or Anthropic?
In my consulting practice, I implement comprehensive fallback routing. If OpenAI rate limits a request, the backend automatically falls back to an equivalent model (like Claude 3 or an Azure-hosted OpenAI instance). I also use queueing systems like BullMQ to stagger non-critical background AI tasks.
What is semantic caching and why do I need it?
Traditional caching requires exact text matches. Semantic caching uses lightweight embeddings to detect when a user asks a question with the same meaning as a previous question, even if phrased differently. This allows you to serve the cached answer instantly, bypassing the LLM provider, saving both time and money.
Which programming language is best for AI backends?
Python (via FastAPI) is the industry standard due to the massive ecosystem of AI libraries (LangChain, LlamaIndex, Pandas). However, Node.js (via Express or NestJS) is entirely capable, especially for streaming implementations, and is often a better choice if your team is already built around TypeScript.
Do I always need a vector database like Pinecone?
Not necessarily. If your application only relies on the internal knowledge of the LLM, you don’t need one. Vector databases are specifically required for RAG (Retrieval-Augmented Generation) when you need the AI to search through your proprietary documents, user data, or corporate wikis before answering.
How long does an AI backend consulting engagement typically last?
It depends on the scope, but generally ranges from 4 to 12 weeks. A pure architectural audit and roadmap might take 2 weeks, while a full ground-up implementation of a secure RAG pipeline and streaming API infrastructure takes closer to 8-12 weeks.
How do you ensure data privacy when using external AI models?
I implement an isolation layer (middleware) before requests leave your servers. This includes PII (Personally Identifiable Information) scrubbers that redact names, emails, and financial data. Additionally, we ensure you are using enterprise-tier API agreements with providers like OpenAI, which guarantee your API data is not used for model training.